Loading...

TL;DR:
- AI-detectie op universiteiten analyseert teksten van studenten met behulp van verschillende technische methoden om het gebruik van AI op te sporen. Hoewel deze tools nuttig zijn, hebben ze ook beperkingen, zoals false positives (onterechte markeringen) en een gebrek aan transparantie, wat studenten onterecht kan benadelen. Het combineren van detectie met procesgerichte beoordelingen en transparant beleid biedt een eerlijkere benadering van academische integriteit.
AI-detectie op universiteiten is het proces waarbij ingeleverde teksten van studenten worden geanalyseerd met statistische en taalkundige methoden om te bepalen of AI-tools hebben bijgedragen aan het schrijfproces. Tools zoals Turnitin, GPTZero en Copyleaks staan inmiddels centraal bij de handhaving van academische integriteit op campussen wereldwijd. Ze meten specifieke schrijfpatronen, genaamd perplexity (voorspelbaarheid) en burstiness (variatie in zinslengte), die menselijk proza onderscheiden van door AI gegenereerde tekst. Begrijpen hoe AI-detectie op universiteiten werkt, geeft zowel studenten als docenten de kennis om eerlijk en verantwoord met deze systemen om te gaan.
Universiteiten vertrouwen op een klein aantal detectieplatforms, die elk een andere technische benadering hanteren. Turnitin, GPTZero en Copyleaks worden het meest gebruikt. Hun nauwkeurigheid varieert van 33% tot 81%, afhankelijk van de methode en context. Die marge is groot genoeg om een wezenlijk verschil te maken. Een tool die er in één op de vijf gevallen naast zit, heeft reële gevolgen voor echte studenten.
Hier is hoe de drie belangrijkste platforms verschillen in hun aanpak:
| Tool | Primaire methode | Belangrijkste sterkte | Gerapporteerde nauwkeurigheid |
|---|---|---|---|
| Turnitin | Vergelijking met statistische taalmodellen | Laag percentage false positives op documentniveau (minder dan 1%) | Hoog op documentniveau |
| GPTZero | Scoren op perplexity en burstiness | Snelle, realtime feedback | Gemiddeld, afhankelijk van de context |
| Copyleaks | Hybride taalkundige en semantische analyse | Transparante, op bewijs gebaseerde rapportage | Varieert per contenttype |
Detectiemethoden vallen uiteen in drie brede categorieën:
Docenten ontvangen rapporten die verdachte passages markeren, waarschijnlijkheidsscores toekennen en in sommige platforms specifieke zinnen uitlichten. Het rapport is een startpunt voor beoordeling, geen definitief vonnis.
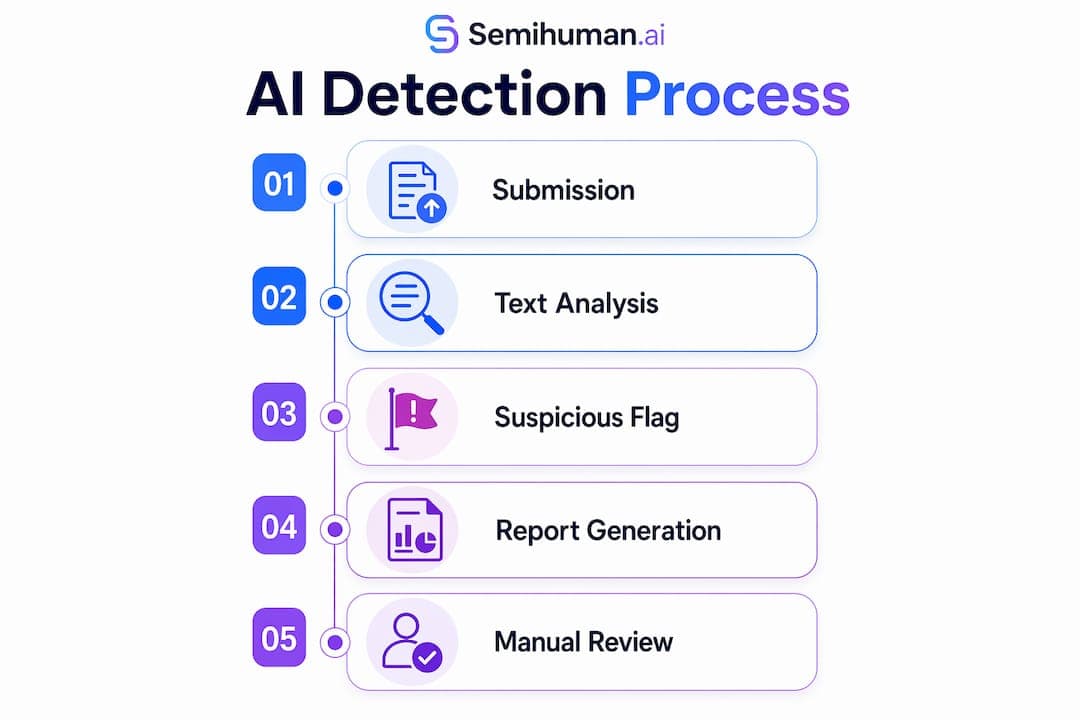
De twee belangrijkste meetwaarden bij AI-detectie zijn perplexity en burstiness. Perplexity meet hoe verrassend of onvoorspelbaar een stuk tekst is. Menselijke schrijvers maken onverwachte woordkeuzes, dwalen wel eens af en variëren in hun ritme. AI-modellen geven de voorkeur aan het statistisch meest waarschijnlijke volgende woord, wat resulteert in tekst die laag scoort op perplexity. Classificatiemodellen behalen betrouwbaarheidsscores van rond de 0,70 bij het onderscheiden van menselijk proza en door AI ondersteunde tekst op basis van deze meetwaarden. Dat is degelijk, maar niet perfect.

Burstiness meet de variatie in zinslengte. Menselijke teksten wisselen vaak korte, krachtige zinnen af met langere, complexere zinnen. AI-teksten zijn veel uniformer. Een alinea waarin elke zin 18 tot 22 woorden telt, is een waarschuwingssignaal (red flag).
Naast deze twee kernwaarden letten detectors en docenten op de volgende specifieke signalen:
Pro-tip: Als je AI-tools gebruikt om je te helpen bij het schrijven, lees je concept dan hardop voor voordat je het inlevert. Zinnen die mechanisch of overdreven vloeiend aanvoelen, zijn precies de zinnen die detectors markeren. Herschrijf die passages in je eigen stem.
Docenten voeren ook handmatige controles uit. Ze kijken of de schrijfstijl overeenkomt met eerder ingeleverd werk van dezelfde student. Een plotselinge verandering in woordenschat of de complexiteit van argumenten is een signaal dat geen enkel algoritme hoeft op te pikken.
AI-detectietools zijn niet betrouwbaar genoeg om als enig bewijs voor fraude te dienen. False positives en de ondoorzichtigheid van de black box blijven de twee grootste problemen bij de handhaving van academische integriteit. Een false positive betekent dat een student die elk woord zelf heeft geschreven, wordt gemarkeerd als AI-gebruiker. Dat is een ernstige vorm van benadeling.
De belangrijkste uitdagingen zijn onder meer:
Het gebrek aan uitlegbaarheid blijft een centraal spanningsveld bij de handhaving van academische integriteit op universiteiten. — International Journal of Machine Learning and Cybernetics
De ethische belangen zijn groot. Een student beschuldigen van academische oneerlijkheid op basis van een waarschijnlijkheidsscore zonder transparante onderbouwing, is geen verdedigbare institutionele praktijk. Docenten hebben tools nodig die hun bevindingen uitleggen, in plaats van ze alleen maar te markeren.
De belangrijkste trend in 2026 is dat AI-detectie niet langer wordt behandeld als een binair disciplinair instrument. De verschuiving gaat richting contextuele, procesgerichte benaderingen die academische integriteit ondersteunen in plaats van alleen overtredingen te bestraffen. Tekstanalyse alleen kan niet het volledige verhaal vertellen van hoe een student een tekst heeft geproduceerd.
Universiteiten voegen de volgende proceslagen toe aan hun detectieworkflows:
Pro-tip: Houd een logboek van je schrijfproces bij voor grote opdrachten. Sla concepten op, noteer je onderzoeksbronnen en houd bij hoeveel tijd je aan het schrijven hebt besteed. Deze documentatie is je beste verdediging als een detectietool je werk onterecht markeert.
Copyleaks biedt transparante rapportage over gemarkeerde content, waardoor docenten op bewijs gebaseerde verklaringen krijgen in plaats van kale scores. Die transparantie maakt een detectierapport pas echt bruikbaar in een gesprek over academische integriteit.
| Beoordelingslaag | Wat het meet | Betrouwbaarheid |
|---|---|---|
| Tekstgebaseerde AI-detectie | Taalkundige patronen, perplexity, burstiness | Gemiddeld (33%–81% nauwkeurigheid) |
| Tracking van toetsaanslagen | Typegedrag, revisiepatronen | Hoog (zeer moeilijk te vervalsen) |
| Vergelijking van schrijfgeschiedenis | Consistentie in stem en stijl | Hoog bij voldoende eerder werk |
| Mondelinge verdediging | Begrip van de ingeleverde content | Zeer hoog |
AI-detectietechnologie op scholen verandert de manier waarop instellingen ingrijpende beslissingen nemen. Sommige toelatingen zijn ingetrokken vanwege mismatches in de schrijfstijl van essays die door detectietools werden opgemerkt. Voorwaardelijke toelatingen en het zakken op wachtlijsten in verband met AI-detectie komen vaker voor dan directe intrekkingen. Dat is een aanzienlijke consequentie voor een systeem dat op waarschijnlijkheid is gebaseerd.
Voor studenten zijn de praktische gevolgen onder meer:
Voor docenten is de uitdaging om een balans te vinden tussen detectie en vertrouwen. Een docent die elke gemarkeerde opdracht als bewijs van fraude behandelt, zal de relatie met studenten schaden en fouten maken. Een betere benadering is om detectierapporten te gebruiken als aanleiding voor een gesprek, niet als een vonnis. Leren om handmatig signalen van AI-gegenereerde essays te herkennen geeft docenten een tweede beoordelingslaag die door geen enkele tool kan worden vervangen.
Universiteiten die een duidelijk beleid rondom AI-gebruik communiceren, zien betere resultaten dan universiteiten die uitsluitend op detectie vertrouwen. Wanneer studenten precies weten wat is toegestaan, maken ze betere keuzes. Wanneer docenten de beperkingen van hun tools kennen, nemen ze eerlijkere beslissingen.
AI-detectie op universiteiten werkt het beste als één laag binnen een breder systeem voor academische integriteit, niet als een op zichzelf staand oordeel.
| Punt | Details |
|---|---|
| Kernwaarden voor detectie | Perplexity en burstiness zijn de belangrijkste signalen die tools gebruiken om AI van menselijk schrijven te onderscheiden. |
| Nauwkeurigheid van tools varieert sterk | De detectienauwkeurigheid varieert van 33% tot 81%, dus geen enkel resultaat van een tool mag als doorslaggevend worden beschouwd. |
| Procesgegevens zijn betrouwbaarder | Het tracken van toetsaanslagen en het vergelijken van de schrijfgeschiedenis zijn moeilijker te vervalsen dan alleen tekstanalyse. |
| False positives zijn een reëel risico | Niet-moedertaalsprekers en formele schrijvers hebben vaker te maken met false positives, wat leidt tot zorgen over eerlijkheid. |
| Transparantie is cruciaal | Tools zoals Copyleaks die op bewijs gebaseerde rapporten leveren, geven docenten verdedigbare gronden voor beslissingen. |
Ik zie al jaren hoe instellingen naar technologie grijpen om een fundamenteel menselijk probleem op te lossen. AI-detectietools zijn nuttig. Ze pikken patronen op die menselijke lezers missen, en ze zijn schaalbaar op een manier die voor individuele docenten onmogelijk is. Maar universiteiten die erop vertrouwen als het laatste woord, maken een fout waar ze zich uiteindelijk voor zullen moeten verantwoorden.
Het probleem van false positives is geen kleine technische voetnoot. Het is een structurele ontwerpfout die studenten zal schaden die niets verkeerd hebben gedaan. Een niet-moedertaalspreker die zorgvuldig en formeel schrijft, zou niet voor een hoorzitting over academisch wangedrag moeten hoeven verschijnen omdat een waarschijnlijkheidsmodel zijn of haar proza te voorspelbaar vond. Dat is geen handhaving van integriteit. Dat is een systeemfout met grote gevolgen.
Wat echt werkt, is de combinatie: een detectiemarkering leidt tot een gesprek, niet tot een straf. De docent kijkt naar de schrijfgeschiedenis van de student, vraagt hem of haar om de argumentatie toe te lichten en controleert of de stem in de ingeleverde tekst overeenkomt met de stem in de kamer. Dat proces is trager. Het vereist menselijk oordeelsvermogen. Het kan niet worden geautomatiseerd. En dat is precies waarom het werkt.
De toekomst van AI in academische evaluaties ligt niet in krachtigere detectors. Het ligt in beter ontworpen opdrachten, duidelijker beleid en docenten die weten hoe ze detectierapporten moeten gebruiken als slechts één van de vele informatiebronnen. De tools zullen blijven verbeteren. Het menselijk oordeel moet daarin meegroeien. Studenten die dit systeem begrijpen, zijn beter in staat om er op een eerlijke manier mee om te gaan en voor zichzelf op te komen wanneer het systeem het bij het verkeerde eind heeft.
— Tilen
Begrijpen hoe detectietools tekst analyseren is de eerste stap naar authentiek schrijven in een door AI ondersteunde wereld. Semihuman is precies voor dit snijvlak gebouwd.
De AI text humanizer van Semihuman herstructureert door AI gegenereerde concepten, zodat ze lezen met de natuurlijke variatie en onvoorspelbaarheid waar detectietools naar zoeken in menselijke teksten. Voor studenten die AI-tools als startpunt gebruiken en willen dat hun uiteindelijke opdracht hun eigen stem weerspiegelt, is dit een praktische workflow. Semihuman biedt ook een AI-gestuurde tekstgenerator die content creëert met authenticiteit die er vanaf het begin is ingebouwd. Ontdek de tools van Semihuman om met vertrouwen en helderheid te schrijven.
Turnitin vergelijkt ingeleverde opdrachten met statistische taalmodellen om tekst te identificeren die te voorspelbaar is. Het percentage false positives ligt onder de 1% op documentniveau, maar stijgt tot ongeveer 4% op zinsniveau.
Perplexity meet hoe onvoorspelbaar een stuk tekst is. Door AI gegenereerde teksten scoren laag op perplexity omdat taalmodellen de voorkeur geven aan statistisch waarschijnlijke woordkeuzes, terwijl menselijk schrijven gevarieerder en verrassender is.
Ja. Studenten die in formeel, gestructureerd Engels schrijven, met name niet-moedertaalsprekers, hebben vaker te maken met false positives omdat hun schrijfpatronen kunnen lijken op AI-output.
Het tracken van toetsaanslagen en mondelinge opvolging zijn de meest betrouwbare methoden. Gedragsstatistieken zoals typepatronen zijn vrijwel onmogelijk te vervalsen, waardoor ze een sterkere indicator zijn dan tekstanalyse alleen.
Openheid is de veiligste aanpak. Universiteiten met een duidelijk beleid voor AI-gebruik rapporteren betere resultaten op het gebied van academische integriteit dan universiteiten die uitsluitend op detectie vertrouwen, en transparantie beschermt studenten tegen beschuldigingen van wangedrag.
Start
Humaniseren
gratis!
Menselijker maken