Loading...

TL;DR:
- Zaznavanje umetne inteligence (UI) na univerzah analizira študentska besedila in s pomočjo različnih tehničnih metod ugotavlja, ali je bila pri pisanju uporabljena pomoč UI. Čeprav so ta orodja uporabna, imajo svoje omejitve, vključno z lažno pozitivnimi rezultati in pomanjkanjem preglednosti, kar lahko študente neupravičeno oškoduje. Združevanje zaznavanja s procesnim ocenjevanjem in jasnimi pravili ponuja pravičnejši pristop k ohranjanju akademske poštenosti.
Zaznavanje UI na univerzah je proces analize oddanih študentskih besedil, ki s pomočjo statističnih in jezikoslovnih metod ugotavlja, ali so k pisanju prispevala orodja umetne inteligence. Orodja, kot so Turnitin, GPTZero in Copyleaks, so danes v središču zagotavljanja akademske poštenosti v kampusih po vsem svetu. Merijo specifične vzorce pisanja, imenovane perpleksnost (stopnja presenečenja) in razgibanost besedila, ki ločujejo človeško prozo od besedil, ki jih ustvari UI. Razumevanje delovanja zaznavanja UI na univerzah daje tako študentom kot profesorjem znanje za pravično in odgovorno uporabo teh sistemov.
Univerze se zanašajo na ožji izbor platform za zaznavanje, pri čemer vsaka uporablja drugačen tehnični pristop. Najbolj razširjena so orodja Turnitin, GPTZero in Copyleaks. Njihova natančnost se giblje med 33 % in 81 %, odvisno od metode in konteksta. Ta razpon je dovolj velik, da je pomemben. Orodje, ki se zmoti v enem od petih primerov, prinaša resnične posledice za resnične študente.
Tukaj je prikazano, kako se tri vodilne platforme razlikujejo v svojem pristopu:
| Orodje | Glavna metoda | Ključna prednost | Poročana natančnost |
|---|---|---|---|
| Turnitin | Primerjava s statističnimi jezikovnimi modeli | Nizka stopnja lažno pozitivnih rezultatov na ravni dokumenta (pod 1 %) | Visoka na ravni dokumenta |
| GPTZero | Ocenjevanje perpleksnosti in razgibanosti | Hitre povratne informacije v realnem času | Zmerna, odvisna od konteksta |
| Copyleaks | Hibridna jezikoslovna in semantična analiza | Pregledno poročanje, podprto z dokazi | Razlikuje se glede na vrsto vsebine |
Metode zaznavanja delimo v tri širše kategorije:
Profesorji prejmejo poročila, ki označijo sumljive odlomke, dodelijo ocene verjetnosti in na nekaterih platformah izpostavijo specifične stavke. Poročilo je izhodišče za presojo, ne pa končna razsodba.
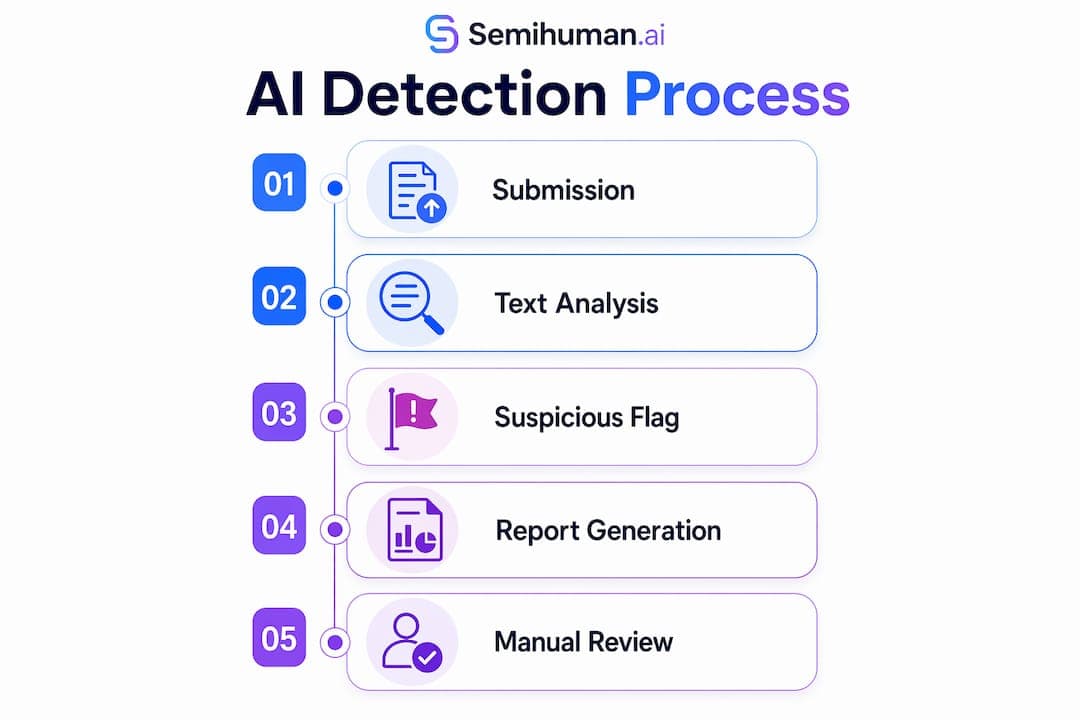
Dve ključni metriki pri zaznavanju UI sta perpleksnost in razgibanost. Perpleksnost meri, kako presenetljivo ali nepredvidljivo je besedilo. Človeški pisci izbirajo nepričakovane besede, zaidejo s teme in spreminjajo ritem. Modeli UI dajejo prednost statistično najverjetnejši naslednji besedi, kar ustvarja besedilo z nizko stopnjo perpleksnosti. Klasifikacijski modeli dosegajo ocene zanesljivosti okoli 0,70, ko s pomočjo teh metrik ločujejo človeško prozo od tiste, ki je nastala s pomočjo UI. To je solidno, a ne popolno.

Razgibanost meri variacijo v dolžini stavkov. Človeško pisanje običajno meša kratke, udarne stavke z daljšimi in kompleksnejšimi. Pisanje UI je bolj enolično. Odstavek, v katerem ima vsak stavek od 18 do 22 besed, je jasen opozorilni znak.
Poleg teh dveh ključnih metrik detektorji in profesorji iščejo še naslednje specifične signale:
Profesionalni nasvet: Če si pri pisanju pomagate z orodji UI, pred oddajo osnutek preberite na glas. Stavki, ki zvenijo mehansko ali preveč gladko, so tisti, ki jih detektorji označijo. Te odlomke popravite tako, da bodo zveneli v vašem lastnem slogu.
Profesorji izvajajo tudi ročna preverjanja. Preverjajo, ali se slog pisanja ujema s prejšnjimi izdelki istega študenta. Nenaden preskok v besedišču ali kompleksnosti argumentacije je signal, za katerega ne potrebujemo nobenega algoritma.
Orodja za zaznavanje UI niso dovolj zanesljiva, da bi služila kot edini dokaz o kršitvi. Lažno pozitivni rezultati in netransparentnost črne škatle ostajata največji težavi pri uveljavljanju akademske poštenosti. Lažno pozitiven rezultat pomeni, da je študent, ki je vsako besedo napisal sam, označen kot uporabnik UI. To predstavlja resno škodo.
Ključni izzivi vključujejo:
Pomanjkanje razložljivosti ostaja osrednja napetost pri uveljavljanju akademske poštenosti na univerzah. — International Journal of Machine Learning and Cybernetics
Etični vložki so visoki. Obtožiti študenta akademske nepoštenosti na podlagi verjetnostne ocene brez pregledne utemeljitve ni sprejemljiva institucionalna praksa. Profesorji potrebujejo orodja, ki svoje ugotovitve pojasnijo, ne le označijo.
Ključni trend v letu 2026 je odmik od obravnavanja zaznavanja UI kot binarnega disciplinskega orodja. Premik gre v smer kontekstualnih, procesno usmerjenih pristopov, ki podpirajo akademsko poštenost, namesto da bi zgolj kaznovali kršitve. Sama analiza besedila ne more povedati celotne zgodbe o tem, kako je študent ustvaril besedilo.
Univerze v svoje delovne procese zaznavanja dodajajo naslednje procesne ravni:
Profesionalni nasvet: Pri večjih nalogah vodite dnevnik procesa pisanja. Shranjujte osnutke, beležite vire raziskovanja in si zapišite čas, ki ste ga porabili za pisanje. Ta dokumentacija je vaša najboljša obramba, če orodje za zaznavanje vaše delo napačno označi.
Copyleaks ponuja pregledno poročanje o označeni vsebini, kar profesorjem zagotavlja na dokazih temelječa pojasnila namesto golih ocen. Prav ta preglednost omogoča, da je poročilo o zaznavanju uporabno v pogovoru o akademski poštenosti.
| Raven ocenjevanja | Kaj meri | Zanesljivost |
|---|---|---|
| Zaznavanje UI na podlagi besedila | Jezikoslovni vzorci, perpleksnost, razgibanost | Zmerna (33 %–81 % natančnost) |
| Sledenje pritiskom na tipke | Tipkarske navade, vzorci popravljanja | Visoka (zelo težko ponarediti) |
| Primerjava zgodovine pisanja | Doslednost glasu in sloga | Visoka ob zadostnem številu prejšnjih del |
| Ustni zagovor | Razumevanje oddane vsebine | Zelo visoka |
Tehnologija zaznavanja UI v šolah preoblikuje način, kako institucije sprejemajo pomembne odločitve. Nekatere ponudbe za vpis so bile preklicane zaradi neskladja v slogu esejev, ki so jih označila orodja za zaznavanje. Pogojne ponudbe in premiki navzdol na čakalnih listah, povezani z zaznavanjem UI, so bolj razširjeni kot neposredni preklici. To je precejšnja posledica za sistem, ki temelji na verjetnosti.
Za študente praktični učinki vključujejo:
Za profesorje je izziv uravnotežiti zaznavanje z zaupanjem. Profesor, ki vsak označen izdelek obravnava kot dokaz goljufanja, bo uničil odnose s študenti in delal napake. Boljši pristop je uporaba poročil o zaznavanju kot povod za pogovor, ne kot razsodbo. Učenje ročnega prepoznavanja znakov esejev, ki jih je ustvarila UI, daje profesorjem dodatno raven presoje, ki je nobeno orodje ne more nadomestiti.
Univerze, ki jasno komunicirajo pravila o uporabi UI, dosegajo boljše rezultate kot tiste, ki se zanašajo zgolj na zaznavanje. Ko študenti natančno vedo, kaj je dovoljeno, sprejemajo boljše odločitve. Ko profesorji poznajo omejitve svojih orodij, sprejemajo pravičnejše odločitve.
Zaznavanje UI na univerzah deluje najbolje kot ena od ravni širšega sistema akademske poštenosti, ne pa kot samostojna razsodba.
| Točka | Podrobnosti |
|---|---|
| Ključne metrike zaznavanja | Perpleksnost in razgibanost sta glavna signala, ki ju orodja uporabljajo za ločevanje UI od človeškega pisanja. |
| Natančnost orodij se močno razlikuje | Natančnost zaznavanja se giblje od 33 % do 81 %, zato rezultata nobenega posameznega orodja ne bi smeli obravnavati kot dokončnega. |
| Podatki o procesu so zanesljivejši | Sledenje pritiskom na tipke in primerjavo zgodovine pisanja je težje ponarediti kot samo analizo besedila. |
| Lažno pozitivni rezultati so resnično tveganje | Tujegovoreči študenti in tisti s formalnim slogom pisanja se soočajo z višjimi stopnjami lažno pozitivnih rezultatov, kar vzbuja pomisleke o pravičnosti. |
| Preglednost je pomembna | Orodja, kot je Copyleaks, ki zagotavljajo na dokazih temelječa poročila, dajejo profesorjem utemeljeno podlago za odločitve. |
Leta sem opazoval, kako institucije posegajo po tehnologiji, da bi rešile nekaj, kar je v osnovi človeški problem. Orodja za zaznavanje UI so uporabna. Ujamejo vzorce, ki jih človeški bralci spregledajo, in omogočajo obdelavo v obsegu, ki ga posamezni profesorji ne zmorejo. Toda univerze, ki se nanje zanašajo kot na zadnjo besedo, delajo napako, za katero bodo sčasoma morale odgovarjati.
Problem lažno pozitivnih rezultatov ni le manjša tehnična opomba. Je strukturna napaka, ki bo oškodovala študente, ki niso storili ničesar narobe. Tujegovoreči študent, ki piše skrbno in formalno, se ne bi smel soočiti z zaslišanjem o akademski nepoštenosti samo zato, ker je verjetnostni model njegovo prozo ocenil kot preveč predvidljivo. To ni uveljavljanje poštenosti. To je sistemska napaka s posledicami.
Tisto, kar dejansko deluje, je kombinacija: opozorilo detektorja sproži pogovor, ne kazni. Profesor pregleda študentovo zgodovino pisanja, ga prosi, naj pojasni svoj argument, in preveri, ali se slog v oddanem izdelku ujema s slogom v živo. Ta proces je počasnejši. Zahteva presojo. Ni ga mogoče avtomatizirati. In prav zato deluje.
Prihodnost UI pri akademskem ocenjevanju niso zmogljivejši detektorji. So bolje zasnovane naloge, jasnejša pravila in profesorji, ki znajo poročila o zaznavanju uporabiti le kot enega od mnogih virov informacij. Orodja se bodo še naprej izboljševala. Skupaj z njimi se mora izboljšati tudi presoja. Študenti, ki razumejo ta sistem, so v boljšem položaju, da v njem delujejo pošteno in se postavijo zase, ko se sistem zmoti.
— Tilen
Razumevanje, kako orodja za zaznavanje analizirajo besedilo, je prvi korak k avtentičnemu pisanju v svetu, ki si pomaga z UI. Semihuman je ustvarjen natanko za to stičišče.
Semihumanov humanizator besedil UI prestrukturira osnutke, ustvarjene z UI, tako da se berejo z naravno variacijo in nepredvidljivostjo, ki jo orodja za zaznavanje iščejo v človeškem pisanju. Za študente, ki orodja UI uporabljajo kot izhodišče in želijo, da njihov končni izdelek odraža njihov lasten slog, je to praktičen potek dela. Semihuman ponuja tudi generator besedil na osnovi UI, ki ustvarja vsebino z vgrajeno avtentičnostjo že od samega začetka. Raziščite orodja Semihuman in pišite samozavestno ter jasno.
Turnitin primerja oddana besedila s statističnimi jezikovnimi modeli, da prepozna besedilo, ki je preveč predvidljivo. Njegova stopnja lažno pozitivnih rezultatov je pod 1 % na ravni dokumenta, vendar naraste na približno 4 % na ravni stavka.
Perpleksnost meri, kako nepredvidljivo je besedilo. Pisanje, ustvarjeno z UI, dosega nizko stopnjo perpleksnosti, ker jezikovni modeli dajejo prednost statistično verjetnim izbiram besed, medtem ko je človeško pisanje bolj raznoliko in presenetljivo.
Da. Študenti, ki pišejo v formalni, strukturirani angleščini, zlasti tisti, ki jim to ni materni jezik, se soočajo z višjimi stopnjami lažno pozitivnih rezultatov, saj so njihovi vzorci pisanja lahko podobni rezultatom UI.
Sledenje pritiskom na tipke in ustno preverjanje sta najbolj zanesljivi metodi. Vedenjske metrike, kot so tipkarski vzorci, je praktično nemogoče ponarediti, zaradi česar so močnejši pokazatelj kot zgolj analiza besedila.
Razkritje je najvarnejši pristop. Univerze z jasnimi pravili o uporabi UI poročajo o boljših rezultatih na področju akademske poštenosti kot tiste, ki se zanašajo zgolj na zaznavanje, preglednost pa študente ščiti pred obtožbami o kršitvah.
Začetek
humanizirati
brezplačno!
Počloveči